Basic Concepts
Computing and storage resources
Computing resource providers offer the computing resources with processing capabilities, such as the grid, HPC centers, and commercial cloud services. A worker node is the minimum unit in each computing resource, which is a (virtual) host, a host cluster, or a slot on a host, depending on workload or resource configuration, and represents a combination of CPUs, memory, and a scratch disk to process workload. Storage resource providers accommodate data storage needs. A storage resource is composed of a persistent data storage with disk, tape, or their hybrid, and a storage management service running on top of it. Association between computing and storage resources can be arbitrary but in most cases resources from the same provider are associated with each other.
PanDA integrates heterogeneous computing and storage resources to provide a consistent interface to users. Users can seamlessly process their workload on computing resources while taking input data from storage resources and uploading output data to storage resources, without paying attention to the details of computing and storage technologies.
Virtual organization
A virtual organization (VO) refers to a dynamic set of individuals defined around a set of resource-sharing rules and conditions. Its members are geographically apart but working for a common objective, such as scientific project, research program, etc.
PanDA components
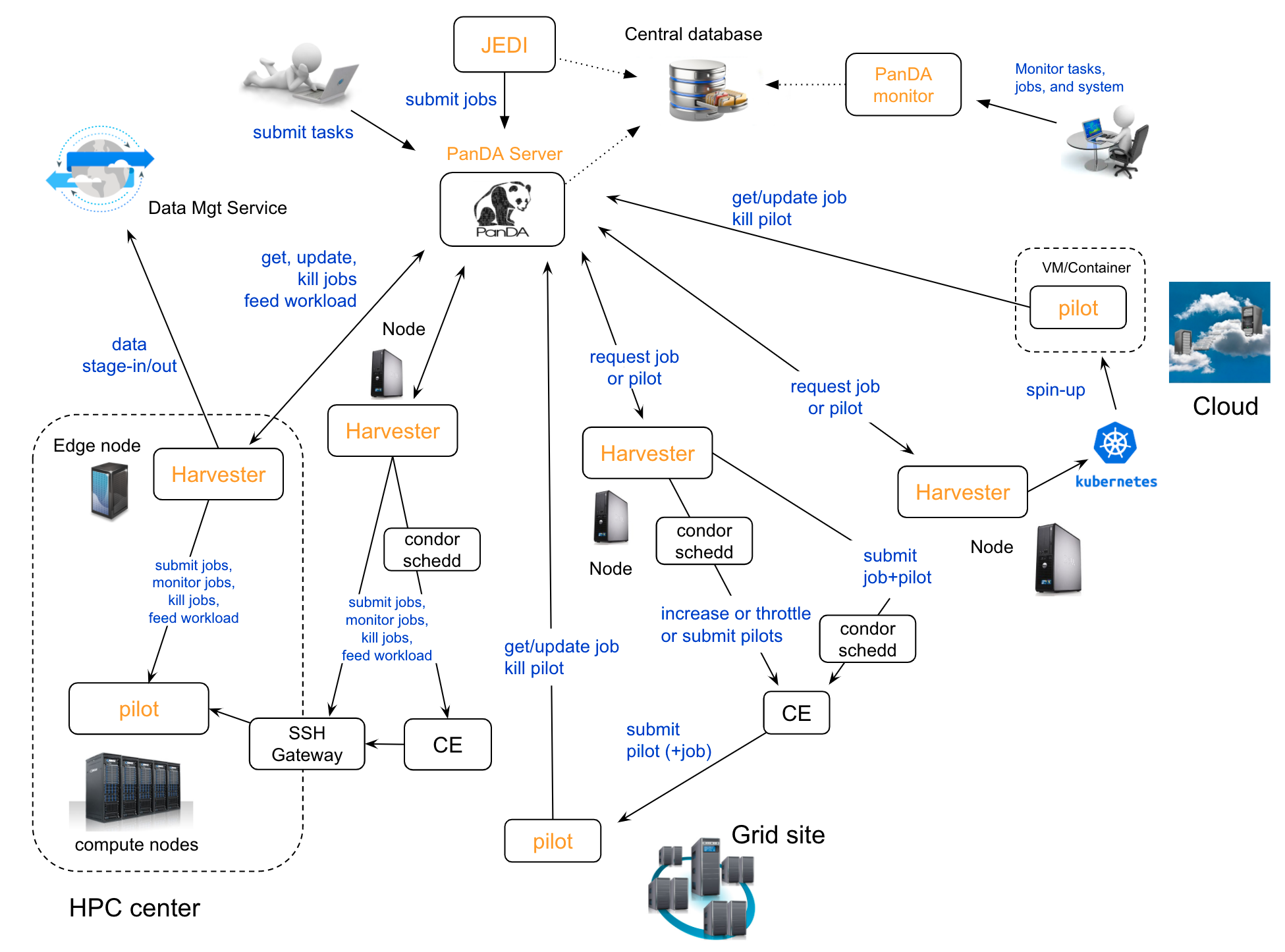
There are five components in the PanDA system, as shown in the schematic view above.
JEDI is a high-level engine to tailor workload for optimal usages of heterogeneous resources dynamically.
PanDA server is the central hub implemented as a stateless RESTful web service to allow asynchronous communication from users, Pilot, and Harvester over HTTPS.
Pilot is a transient agent to execute a tailored workload (= a job: to be explained in a following section) on a worker node, reporting periodically various metrics to the PanDA server throughout its lifetime.
Harvester provisions the Pilot on resources using the relevant communication protocol for each resource provider and communicates with PanDA server on behalf of the Pilot if necessary.
PanDA monitor is a web-based monitoring of tasks and jobs processed by PanDA, providing a common interface for end users, central operations team and remote site administrators.
JEDI and the PanDA server share the central database to record the status of tasks and jobs. PanDA monitor reads this central database to offer the different views. Harvester uses its own more lightweight and more transient database, which can be either central or local depending on the deployment model. PanDA components and database are explained in System Architecture and Database pages, respectively.
Task
A task is a unit of workload to accomplish an indivisible scientific objective. If an objective is done in multiple steps, each step is mapped to a task. A task takes input and produces output. The goal of the task is to process the input entirely. Generally, input and output are collections of data files, but there are also other formats, such as a group of sequence numbers, metadata, notification, void, etc. Each task has a unique identifier JediTaskID in the system.
Task status changes as shown in the following figure.
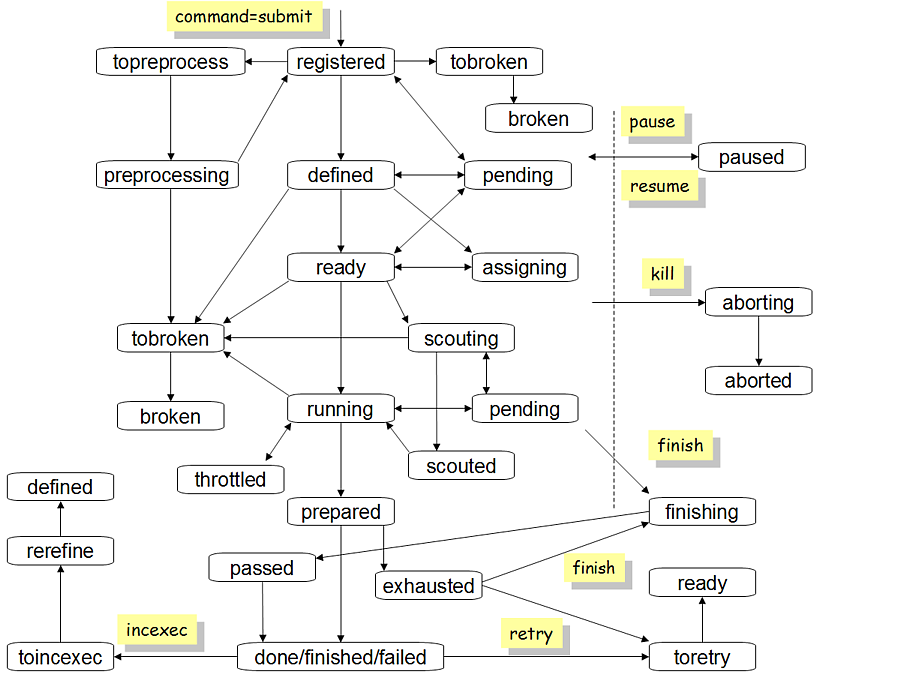
Yellow boxes in the figure show the commands sent to PanDA by external actors to trigger task status transition. Here is the list of task statuses and their descriptions.
- registered
The task was injected into PanDA.
- defined
All task parameters were properly parsed.
- assigning
The task is being assigned to a storage resource.
- ready
The task is ready to generate jobs.
- pending
The task has a temporary problem or is waiting for an input; e.g. there are no free computing resources for new jobs.
- scouting
The task is running scout jobs to gather job metrics.
- scouted
Enough number of scout jobs were successfully finished and job metrics were calculated.
- running
The task avalanches to generate more jobs.
- prepared
The workload of the task was done, and the task is ready to run the postprocessing step.
- done
The entire workload of the task was successfully processed.
- failed
The entire workload of the task was failed.
- finished
The workload of the task partially succeeded.
- aborting
The task got the
killcommand.- aborted
The task was killed.
- finishing
The task got the
finishcommand to terminate processing while it was still running.- topreprocess
The task is ready to run the preprocessing step.
- preprocessing
The task is running the preprocessing step.
- tobroken
The task is going to be broken.
- broken
The task is broken, e.g., due to wrong parameters.
- toretry
The task got the retry command.
- toincexec
The task got the
incexec(incremental execution) command to retry a task with new task parameters after looking up the input data. This is typically useful when new data are appended to the input data and require changes in some task parameters.- rerefine
The task is changing parameters for incremental execution.
- paused
The task is paused and doesn’t do anything until it gets the
resumecommand.- throttled
The task is throttled not to generate new jobs.
- exhausted
Indicating that the system gave up processing the task due to persistent failures, inefficiencies, or resource-related issues, and user intervention or reconfiguration is required.
Job
A job is an artificial workload sub-unit partitioned from a task. A single task is composed of multiple jobs, and each job runs on the minimum set of the computing resource. Each job is tailored based on the user’s preference (if any) and/or constraints of the computing resource. For example, if the job size is flexible, jobs are generated to have a short execution time and produce small output files when being processed on resources with limited time slots and local scratch disk spaces. The task input is logically split into multiple subsets, and each job gets a subset to produce output. The collection of job output is the task output. Each job has a unique identifier PanDA ID in the system. Generally, one pilot processes one job on a worker node. However, it is possible to configure the pilot to process multiple jobs sequentially or concurrently on a worker node if the computing resources allow such configurations, reducing the number of interactions with those resources.
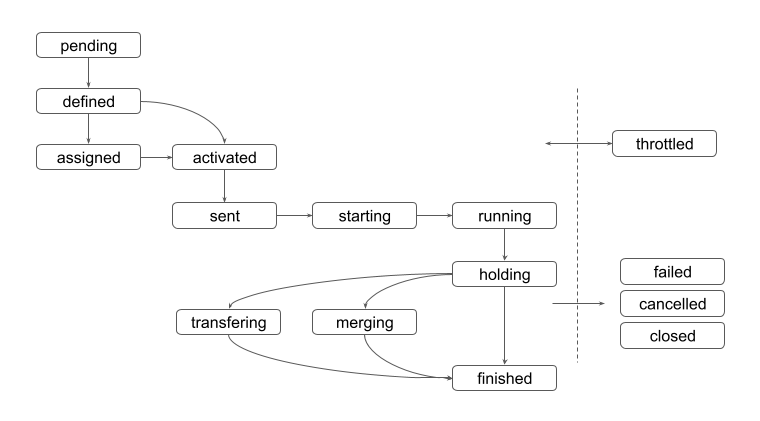
The status of jobs sequentially changes as follows:
- pending
The job is generated.
- defined
The job is ready to work for global input data motion if necessary. E.g., data transfer from a remote storage resource to the “local” storage resource close to the computing resource.
- assigned
Input data are being transferred to the “local” storage resource. This status is skipped if the job doesn’t need global input data motion or physical input data.
- activated
The input data has been transferred correctly and the job is ready to be fetched by a running pilot.
- sent
The job was fetched by a pilot running on the computing resource.
- starting
The job has been retrieved from PanDA server, but has not started running yet. Jobs in this status could be working for the last-mile input data motion, such as data stage-in from the “local” storage to the scratch disk attached to the worker node. Alternatively, for push queues, jobs in starting status could have been retrieved by the pilot submitter (Harvester, ARC Control Tower,…), but is still queued in the batch system.
- running
The job is processing input data.
- holding
The job finished processing, released the computing resource, reported the final metrics to the PanDA server, uploaded output files to the local storage. Note that jobs don’t use any computing resources any longer in this and subsequent job statuses.
- merging
Output data are being merged. This status is skipped unless the task is configured to merge job output.
- transferring
Output data are being transferred from the local storage to the final destination.
And goes to one of the final statues described below:
- finished
The job successfully produced output, and it is available at the final destination.
- failed
The job failed during execution or data management.
- closed
The system terminated the job before running on a computing resource.
- cancelled
The job was manually aborted.
Scout job
Each task generates a small number of jobs using a small portion of input data. They are scout jobs to collect various metrics such as data processing rate and memory footprints. Tasks use those metrics to generate jobs for remaining input data more optimally.
Brokerage
There are two brokerages in JEDI: task brokerage and job brokerage.
The task brokerage assigns tasks to storage resources if those tasks are configured to aggregate output, but final destinations are undefined.
On the other hand, the job brokerage assigns jobs to computing resources. A single task can generate many jobs, and they can be assigned to multiple computing resources unless the task is configured to process the whole workload at a single computing resource. The details of brokerage algorithms are described in the Brokerage page.
Pull and push
Users submit tasks to JEDI through the PanDA server, JEDI generates jobs on behalf of users and passes them to the PanDA server and the PanDA server centrally pools the jobs. There are two modes for the PanDA server to dispatch jobs to computing resources: the pull and push modes.
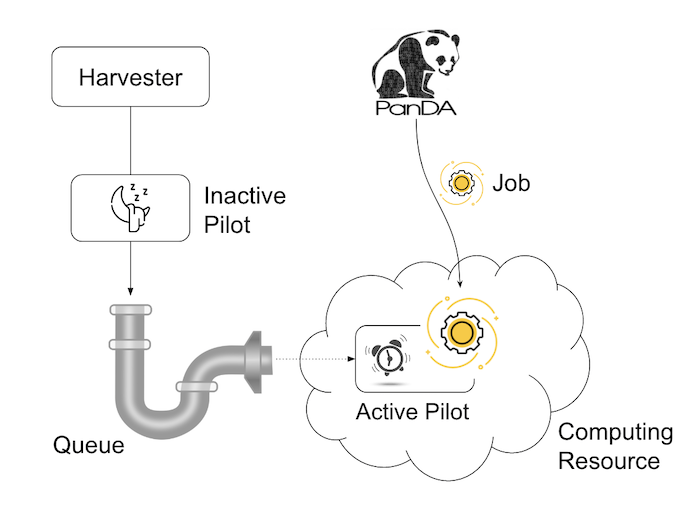
In pull mode, blank pilots are provisioned first on computing resources, and they fetch jobs once CPUs become available. It is possible to trigger the pilot provisioning well before generating jobs. Thus jobs can start processing as soon as they are generated, even if there is long latency for provisioning in the computing resource. Another advantage is the capability to postpone the decision making to bind jobs with CPUs until the last minute, which allows fine-grained job scheduling with various job attributes, e.g. increasing the chance for new jobs with a higher priority share to jump over old jobs in a lower priority share.
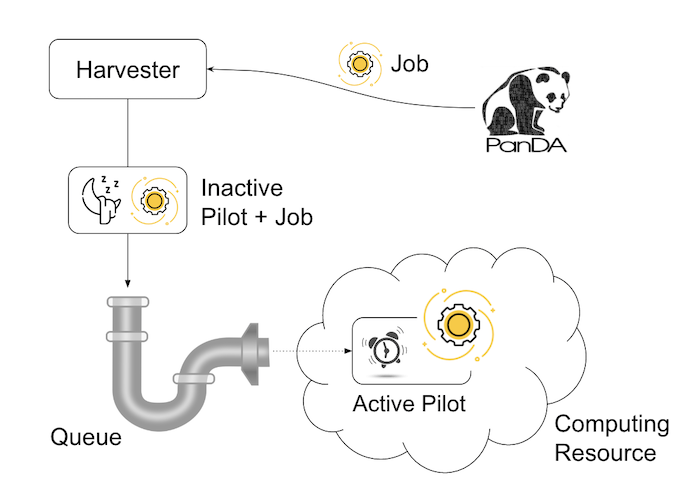
On the other hand, in push mode pilots are provisioned on computing resources together with a preassigned jobs. Job scheduling merely relies on the scheduling mechanisms in the computing resources. The pilot specifies requirements for each job. The mechanisms dynamically configure a worker with CPUs, memory size, execution time limit, and so on, which is typically more optimal for special resources like HPCs and GPU clusters.
Heartbeat
The pilot periodically sends heartbeat messages to the PanDA server via a short-lived HTTPS connection to report various metrics while executing a job on a worker node. Heartbeats guarantee that the pilot is still alive as the PanDA server and the pilot don’t maintain a permanent network connection. If the PanDA server doesn’t receive heartbeats from the pilot during a specific period, the PanDA server presumes that the pilot is dead and kills the job being executed by the pilot.
Users
Users process workloads on PanDA to accomplish their objectives. PanDA authenticates and authorizes them to access the computing and storage resources based on their profile information. The Identity and access management page explains the details of PanDA’s authentication and authorization mechanism. Users can be added to one or more working groups in the identity and access management system to process “public” workloads for those communities. Resource usages of private and public workloads are separated. Tasks and jobs have the working group attribute to indicate for which working groups they are.
Priority
The priority of a task or job determines which task or job has precedence over other competing tasks or jobs in the same global share. Their priorities are relevant in each global share: i.e. high-priority tasks in a global share don’t interfere with low-priority tasks in another global share. Generally jobs inherit the priority of its task, but scout jobs have higher priorities to collect various metrics as soon as possible.
Task and job retry
It is possible to retry tasks if a part of input data were not successfully processed or new data were added to input data. The task status changes from finished or done back to running, and output data are appended to the same output data collection. Tasks cannot be retried if they end up with a fatal status, such as broken and failed since they are hopeless and not worth retrying.
On the other hand, the job status is irreversible, i.e., jobs don’t change their status once they go to a final status. JEDI generates new jobs to re-process the input data portion, which was not successfully processed by previous jobs. Configuration of retried jobs can be optimized based on experiences with previous jobs (e.g. increased memory requirements). It is also possible to configure rules to avoid the job retrial for hopeless error codes/messages.