Brokerage
The brokerage is one of the most crucial functions in the system to distribute workload among computing resources. It has the following goals:
To assign enough jobs to computing resources to utilize all available CPUs continuously.
To minimize the waiting time for each job to produce output data.
To execute jobs in such a way that the jobs respect their priorities and resource allocations.
To choose computing resources for each job based on characteristics of the job and constraints of the computing resources.
It is not straightforward to satisfy those goals for all jobs since some of them are logically contradictory. The brokerage has a plugin structure so that organizations can provide their algorithms according to their needs and use-cases.
This page explains the algorithms of some advanced plugins.
Note
System configuration parameters referenced as SOME_PARAM in the following
sections are stored in the database table described in
gdpconfig.
ATLAS Production Task Brokerage
The ATLAS production task brokerage assigns each task to a nucleus as follows:
Generate the primary list of nuclei in the ACTIVE status.
Filter out the list with the following checks:
Nuclei are skipped if there are long transfer backlogs unless
t1Weightof the task is negative.Nuclei must have associated storages.
The storages associated with nuclei must have enough space:
\[spaceUsable - normalizedExpOutSize \times RW > diskThreshold\]where:
spaceUsable is the amount of storage available for new data on the associated storage endpoint. It is computed as:
\[spaceUsable = spaceFree + spaceExpired - minFreeSpace - spaceUnavailable\]where spaceFree is the currently free space, spaceExpired is the reclaimable space occupied by expired secondary data, minFreeSpace is the minimum free space that must be preserved, and spaceUnavailable is the space reserved for scheduled data transfers.
normalizedExpOutSize is the expected output size normalized by cpuTime × corePower × day (0.25), and RW is the total amount of existing workload assigned to the nucleus. Their product, normalizedExpOutSize × RW, is the projected storage demand of the assigned workload.
diskThreshold is the minimum storage that must remain available after accounting for the projected storage demand. It is configured per gshare using
DISK_THRESHOLD_<gshare>. If no gshare-specific value is defined,DISK_THRESHOLDis used instead, with a default value of 100 TB.
The storages associated to nuclei must be able to send input files to satellites and receive output files from sattellites over WAN, i.e., their
read_wanandwrite_wanmust beON.Nuclei must pass the data locality check with the following rules:
All input datasets are considered if the
taskBrokerOnMastertask parameter is set to False or is unspecified. Otherwise, only the primary input dataset is considered, i.e., secondary datasets are ignored.Nuclei with incomplete local data can be used if the
inputPreStagingtask parameter is set to True since the parameter enables the data carousel mode and guarantees the input data completeness. Those nuclei ignore the next two rules with the input data size and the number of input files.The fraction of the data size locally available divide by the total input size must be larger than
INPUT_SIZE_FRACTIONif the total input size is larger thanINPUT_SIZE_THRESHOLD.The fraction of the number of files locally available divide by the total number of input files must be larger than
INPUT_NUM_FRACTIONif the total input size is larger thanINPUT_NUM_THRESHOLD.The entire data locality check is disabled if no nuclei pass and
ioIntencityof the task is less than or equal toMIN_IO_INTENSITY_WITH_LOCAL_DATAand the total input size is less than or equal toMIN_INPUT_SIZE_WITH_LOCAL_DATA, ortaskPriorityof the task is larger than or equal toMAX_TASK_PRIO_WITH_LOCAL_DATA.
Calculate brokerage weight for remaining nuclei using the following formula to choose a nuclei based on that:
When
ioIntencityof the task is greater thanMIN_IO_INTENSITY_WITH_LOCAL_DATA\[weight =\frac {localInputSize \times tapeWeight \times (spaceFree + spaceExpired) \times min(spaceFreeCutoff, spaceFree)} {max(rwOffset, RW) \times totalInputSize \times spaceTotal}\]Otherwise,
\[weight =\frac {tapeWeight \times (spaceFree + spaceExpired) \times min(spaceFreeCutoff, spaceFree)} {max(rwOffset, RW) \times spaceTotal}\]where localInputSize is the size of input data locally available, totalInputSize is the total size of input data, tapeWeight is 0.001 if input data is on the tape storage, or 1 otherwise, rwOffset is 50 to have the minimum offset for RW, spaceFreeCutoff is the maximum free disk space value that will be factored into the calculation (
FREE_DISK_CUTOFF), and spaceTotal is the total size of the storage.If all nuclei are skipped, the task is pending for 30 min and then gets retried.
ATLAS Production Job Brokerage
Here is the ATLAS production job brokerage flow:
Generate the list of preliminary candidates from one of the following:
All queues while excluding any queue with case-insensitive ‘test’ in the name.
A list of pre-assigned queues. Unified queues are resolved to pseudo-queues. Although merge jobs are pre-assigned to avoid transferring small pre-merged files, the pre-assignment is ignored if the relevant queues have been skipped for 24 hours.
Filter out preliminary candidates that don’t pass any of the following checks:
The queue status must be online unless the queues are pre-assigned.
Skip queues if their links to the nucleus are blocked.
Skip queues if over the
NQUEUED_SAT_CAPfiles queued on their links to the nucleus.Skip all queues if the number of files to be aggregated to the nucleus is larger than
NQUEUED_NUC_CAP_FOR_JOBS.If priority ≥ 800 or scout jobs or merging jobs or pre-merged jobs, skip inactive queues (where no jobs got started in the last 2 hours although activated jobs had been there).
If priority ≥ 800 or scout jobs, skip opportunistic queues (defined as queues with
pledgedcpu=-1).Zero Share, which is defined in the
fairsharepolicyfield in CRIC. For example type=evgen:100%,type=simul:100%,type=any:0%, in this case, only evgen or simul jobs can be assigned as others have zero shares. See a more detailed description further below in this page.If the task
ioIntensityis larger thanIO_INTENSITY_CUTOFF, the total size of missing files must be less thanSIZE_CUTOFF_TO_MOVE_INPUTand the number of missing files must be less thanNUM_CUTOFF_TO_MOVE_INPUT. I.e., if a queue needs to transfer more input files, the queue is skipped.There is a general
MAX_DISKIO_DEFAULTlimit. It is possible to overwrite the limit for a particular queue through themaxDiskIO(in kB/sec per core) field in CRIC. The limit is applied in job brokerage: when the average diskIO per core for running jobs in a queue exceeds the limit, the next cycles of job brokerage will exclude tasks withdiskIOhigher than the defined limit to progressively get the diskIO under the threshold.CPU Core count matching amount site.coreCount, task.coreCount, and maxCoreCount of the task if defined.
Availability of ATLAS release/cache. This check is skipped when queues have ANY in the
releasesfiled in CRIC. If queues have AUTO in thereleasesfiled, the brokerage uses the information published in a json by CRIC as explained at this section.Queues publish maximum (and minimum) memory size per core. The expected memory site of each job is estimated for each queue as
\[(baseRamCount + ramCount \times coreCount) \times compensation\]where compensation is 0.9, avoiding sending jobs to high-memory queues when their expected memory usage is close to the lower limit. Queues are skipped if the estimated memory usage is not included in the acceptable memory ranges.
Skip queues if they don’t support direct access to read input files from the local storage, although the task is configured to use only direct access.
The disk usage for a job is estimated as
\[inputDiskCount + max (1.5 GB, outDiskCount \times nEvents \: or \: outDiskCount \times inputDiskCount) + max (300 MB, workDiskCount)\]inputDiskCount is the total size of job input files, a discrete function of nEvents. nEvents is the smallest number of events in a single job allowed based on the task requirements and is used to estimate the output size by multiplying outDiskCount when outDiskCountUnit ends with “PerEvents”, otherwise, inputDiskCount is used. inputDiskCount is zero if the queues are configured to read input files directly from the local storage.
maxwdiris divided by coreCount at each queue and the resultant value must be larger than the expected disk usage.DISK size check, usable space in the local storage has to be over
STORAGE_MIN_FREE_SIZE.Skip queues if their storage endpoints are blacklisted:
For all queues.
Input endpoints must be locally readable over LAN (
read_lan=ON).Output endpoints must be locally writable over LAN (
write_lan=ON).
For sattelite queues in addition:
Input endpoints must be able to receive files over WAN (
write_wan=ON).Output endpoints must be able to send files over WAN (
read_wan=ON).The nucleus storage endpoints must allow receivng and sending files over WAN (
write_wan=ONandread_wan=ON).
For scout or walltime-undefined jobs, skip queues if their
maxtimeis less than 24 hours.The estimated walltime for a job is
\[\frac {cpuTime \times nEvents} {C \times P \times cpuEfficiency} + baseTime\]nEvents is the same as the one used to estimate the disk usage. The estimated walltime must be between
mintimeandmaxtimeat the queue.wnconnectivityof the queue must be consistent if the task specifiesipConnectivity. The format ofwnconnectivityandipConnectivityisnetwork_connectivity#ip_stack. network_connectivity of the queue isfull: to accept any tasks since outbound network connectivity is fully available,
http: to accept tasks with network_connectivity=http or none since only http access is available, or
none: to accept tasks with network_connectivity=none since no outbound network connectivity is available,
ip_stack of the queue is
IPv4: to accept tasks with ip_stack=IPv4,
IPv6: to accept tasks with ip_stack=IPv6, or
‘’ (unset): to accept tasks without specifying ip_stack.
Settings for event service and the dynamic number of events.
Too many transferring jobs: skip if transferring > max(transferring_limit, 2 x running), where transferring_limit limit is defined by site or 2000 if undefined.
Use only the queues associated with the nucleus if the task sets
t1Weight=-1and normal jobs are being generated.Skip queues without pilots for the last 3 hours.
If processingType=*urgent* or priority ≥ 1000, the Network weight must be larger than or equal to
NW_THRESHOLD×NW_WEIGHT_MULTIPLIER.When
WORK_SHORTAGEis set to True, the following queues are skipped:Opportunistic queues defined with
pledgedcpu=-1.Partially pledged queues defined with positive
pledgedcpuwhen the total number of running cores is larger thanpledgedcpu.
Calculate brokerage weight for remaining candidates. The initial weight is based on running vs queued jobs. The brokerage uses the largest one as the number of running jobs among the following numbers:
The actual number of running jobs at the queue, Rreal.
min(nBatchJob, 20) if Rreal < 20 and nBatchJob (the number of running+submitted batch workers at PQ) > Rreal. Mainly for bootstrap.
numSlots if it is set to a positive number for the queue to the proactive job assignment.
The number of starting jobs if numSlots is set to zero, which is typically useful for Harvester to fetch jobs when the number of available slots dynamically changes.
The number of assigned jobs is ignored for the weight calculation and the subsequent filtering if the input for the jobs being considered is already available locally. Jobs waiting for data transfer do not block new jobs needing no transfer.
\[manyAssigned = max(1, min(2, \frac {assigned} {activated}))\]\[weight = \frac {running + 1} {(activated + assigned + starting + defined + 10) \times manyAssigned}\]Take data availability into consideration.
\[weight = weight \times \frac {availableSize + totalSize} {totalSize \times (numMissingFiles / 100 + 1)}\]Apply a Network weight based on connectivity between nucleus and satellite, since the output files are aggregated to the nucleus.
\[weight = weight \times networkWeight\]Apply further filters.
Skip queues if activated + starting > 2 × running.
Skip queues if defined+activated+assigned+starting > 2 × running.
If all queues are skipped, the task is pending for 1 hour. Otherwise, the remaining candidates are sorted by weight, and the best 10 candidates are taken.
Release/cache Availability Check for releases=AUTO
Each queue publishes something like
"AGLT2": {
"cmtconfigs": [
"x86_64-centos7-gcc62-opt",
"x86_64-centos7-gcc8-opt",
"x86_64-slc6-gcc49-opt",
"x86_64-slc6-gcc62-opt",
"x86_64-slc6-gcc8-opt"
],
"containers": [
"any",
"/cvmfs"
],
"cvmfs": [
"atlas",
"nightlies"
],
"architectures": [
{
"arch": ["x86_64"],
"instr": ["avx2"],
"type": "cpu",
"vendor": ["intel","excl"]
},
{
"type": "gpu",
"vendor": ["nvidia","excl"],
"model":["kt100"],
"version": "11.0.3",
}
],
"tags": [
{
"cmtconfig": "x86_64-slc6-gcc62-opt",
"container_name": "",
"project": "AthDerivation",
"release": "21.2.2.0",
"sources": [],
"tag": "VO-atlas-AthDerivation-21.2.2.0-x86_64-slc6-gcc62-opt"
},
{
"cmtconfig": "x86_64-slc6-gcc62-opt",
"container_name": "",
"project": "Athena",
"release": "21.0.38",
"sources": [],
"tag": "VO-atlas-Athena-21.0.38-x86_64-slc6-gcc62-opt"
}
]
}
Checks for CPU and/or GPU Hardware
The old format of task architecture is sw_platform<@base_platform><#host_cpu_spec><&host_gpu_spec> where
host_cpu_spec is architecture<-vendor<-instruction_set>> and
host_gpu_spec is vendor<-model>.
It is possible to use regexp in the architecture field of host_cpu_spec like “(x86_64|aarch64)” to be matched
with x86_64 or aarch64 queues.
If #host_cpu_spec is not specified in task’s architecture, the first part of sw_platform is used as
CPU architecture.
The regexp in sw_platform is resolved to a relevant string in the cmtconfigs list of the queue.
The new format of task architecture is a JSON-serialized dictionary with the following keys: sw_platform, base_platform,
cpu_specs, and gpu_spec.
The cpu_specs is a list of dictionaries with the following keys: arch, instr, type, and vendor.
The gpu_spec is a dictionary with the following keys:
vendor: GPU vendor regexp (e.g.NVIDIA). Use*for any vendor.model: either a plain regular expression string for inclusion, or a dictionary withpatternandexclkeys for exclusion. Matching is case-insensitive, so.*A100.*and.*a100.*are equivalent. For example,{"model": ".*A100.*"}requires an A100 GPU, while{"model": {"pattern": ".*P100.*", "excl": true}}excludes any queue with a P100 GPU.version: optional CUDA toolkit version constraint as an operator-prefixed string (e.g.">=12.0"). Supports==,=,>=,<=,>,<,!=(=is treated as==).vram: optional GPU memory constraint in MB, as an operator-prefixed string (e.g.">=40960"for at least 40 GB,"==15360"or"=15360"for exactly 15 GB). Supports==,=,>=,<=,>,<,!=(=is treated as==).microarchitecture: optional GPU microarchitecture generation or list of generations (e.g."Ampere"or["Ampere", "Hopper", "Ada Lovelace"]).driver_version: optional GPU kernel driver version constraint as an operator-prefixed string (e.g.">=575.0"). This refers to the NVIDIA kernel driver (e.g.575.57.08,580.82.07), distinct from the CUDA toolkit version. Supports the same operators asvram.
The brokerage uses a two-stage approach for GPU queue selection:
Capability gate — CRIC is used to determine whether a queue is GPU-capable. A queue is considered GPU-capable if it has a
gpuentry in its architecture specification. Queues without a GPU entry in CRIC are skipped immediately, regardless of what worker node monitoring reports.Attribute matching — for GPU-capable queues, all attribute checks (
vendor,model,vram,microarchitecture,version,driver_version) are performed against the worker node GPU monitoring data (MV_WORKER_NODE_GPU_SUMMARY), which aggregates GPU hardware information reported directly by pilots. This data is richer and more up to date than CRIC, and includes fields such as VRAM, GPU microarchitecture generation, CUDA toolkit version, and kernel driver version. If a queue is GPU-capable per CRIC but has no entry in the monitoring data, it is accepted for wildcard requests (no specific attribute required) and rejected when specific attributes are requested.
Mixed-node queues: For minimum-requirement attributes (version, driver_version, vram), a queue is only accepted if all worker nodes in that queue satisfy the constraint. If even one node falls below the requirement — for example a queue with a mix of CUDA 12.2 and CUDA 12.9 nodes when the task requires >=12.8 — the queue is excluded entirely. This prevents jobs from being dispatched to a queue where they could land on a non-compliant node. Selection attributes (vendor, model, microarchitecture) use an any match: the queue is accepted if at least one node has that GPU type.
GPU requirements can be expressed either as a compact shorthand string or as a full JSON dictionary.
Shorthand format (used in ART test headers and on the prun/pathena command line):
The &vendor part of the architecture string identifies GPU requirements. Additional attributes are appended as colon-separated key<op>value pairs, where <op> is one of ==, >=, <=, >, <, !=. Single = is also accepted and treated as == (exact match). For the model key, != expresses exclusion (e.g. model!=.*P100.* excludes queues with P100 GPUs).
Attribute |
Shorthand key |
Example value |
|---|---|---|
Vendor |
positional (after |
|
Model inclusion (regexp) |
|
|
Model exclusion (regexp) |
|
|
VRAM (MB) |
|
|
CUDA toolkit version |
|
|
GPU microarchitecture |
|
|
Kernel driver version |
|
|
Examples with prun / pathena:
# any NVIDIA GPU
prun --architecture '#&nvidia' ...
# NVIDIA GPU with at least 40 GB VRAM
prun --architecture '#&nvidia:vram>=40960' ...
# NVIDIA GPU with exactly 15 GB VRAM
prun --architecture '#&nvidia:vram==15360' ...
# NVIDIA GPU on Ampere microarchitecture with CUDA >= 12.0
prun --architecture '#&nvidia:uarch=Ampere:cuda>=12.0' ...
# NVIDIA A100 with at least 40 GB VRAM and kernel driver >= 575.0
prun --architecture '#&nvidia:model=.*A100.*:vram>=40960:driver>=575.0' ...
# any NVIDIA GPU excluding P100
prun --architecture '#&nvidia:model!=.*P100.*' ...
# any NVIDIA GPU excluding P100 or V100
prun --architecture '#&nvidia:model!=.*(P100|V100).*' ...
Examples in ART test headers:
# any NVIDIA GPU
# art-architecture: '#&nvidia'
# NVIDIA A100 with at least 40 GB VRAM
# art-architecture: '#&nvidia:model=.*A100.*:vram>=40960'
# NVIDIA GPU with CUDA >= 12.0 on Ampere microarchitecture
# art-architecture: '#&nvidia:cuda>=12.0:uarch=Ampere'
# NVIDIA A100, exactly 80 GB VRAM, CUDA >= 12.0, kernel driver >= 575.0
# art-architecture: '#&nvidia:model=.*A100.*:vram==81920:cuda>=12.0:driver>=575.0'
# any NVIDIA GPU excluding P100 or V100
# art-architecture: '#&nvidia:model!=.*(P100|V100).*'
JSON format (usable for all filters, including model exclusion):
# any NVIDIA GPU with at least 40 GB VRAM and CUDA >= 12.0
prun --architecture '{"gpu_spec": {"vendor": "nvidia", "vram": ">=40960", "version": ">=12.0"}}'
# NVIDIA A100, Ampere microarchitecture, kernel driver >= 575.0
prun --architecture '{"gpu_spec": {"vendor": "nvidia", "model": ".*A100.*", "microarchitecture": "Ampere", "driver_version": ">=575.0"}}'
# any NVIDIA GPU excluding P100, at least 40 GB VRAM
prun --architecture '{"gpu_spec": {"vendor": "nvidia", "model": {"pattern": ".*P100.*", "excl": true}, "vram": ">=40960"}}'
# any NVIDIA GPU excluding P100 and V100
prun --architecture '{"gpu_spec": {"vendor": "nvidia", "model": {"pattern": ".*(P100|V100).*", "excl": true}}}'
Examples in ART test headers (JSON format):
# any NVIDIA GPU with at least 40 GB VRAM and CUDA >= 12.0
# art-architecture: {"gpu_spec": {"vendor": "nvidia", "vram": ">=40960", "version": ">=12.0"}}
# any NVIDIA GPU excluding P100 and V100
# art-architecture: {"gpu_spec": {"vendor": "nvidia", "model": {"pattern": ".*(P100|V100).*", "excl": true}}}
Warning
ART passes the art-architecture header value literally to prun — unlike the shell command line where
surrounding quotes are stripped. Do not wrap the JSON in single quotes in the header. Using
# art-architecture: '{"gpu_spec": ...}' will cause prun to receive a string starting with ',
which silently fails JSON parsing and results in the test appearing as missing rather than failed.
Note
For model exclusion, pattern and excl must be nested inside model as a dictionary. Placing them at the top level of gpu_spec will silently have no effect. The regex follows Python re.match semantics and is case-insensitive, so .*(P100|V100).* correctly matches both Tesla V100S-PCIE-32GB and Tesla P100-PCIE-16GB.
If host_cpu_spec or host_gpu_spec is specified, the brokerage checks the architectures of the queue (shown in the above example).
The architectures can contain two dictionaries to describe CPU and GPU hardware specifications at the queue.
All attributes of the
dictionaries except for the type attribute take lists of strings. If ‘attribute’: [‘blah’], the queue
accepts tasks with attribute=’blah’ or without specifying the attribute. If ‘excl’ is included in the list,
the queue accepts only tasks with attribute=’blah’.
For example, tasks with #x86_64 are accepted by queues with “arch”: [“x86_64”], “arch”: [“”],
or “arch”: [“x86_64”, “excl”], but not by “arch”: [“arm64”].
Checks for Fat Containers
If the task uses a container, i.e., the container_name attribute is set, the brokerage checks as follows:
If the task uses only tags, i.e., it sets
onlyTagsForFC, thecontainer_namemust be equal to the container_name of a tag in thetagslist or must be included in thesourcesof a tag in thetagslist.If the task doesn’t set
onlyTagsForFC,‘any’ or ‘/cvmfs’ must be included in the
containerslist, orcontainer_namemust be forward-matched with one of the strings in thecontainerslist, orcontainer_nameis resolved to the source path using the dictionary of the “ALL” queue, and the resolved source path must be forward-matched with one of the strings in thecontainerslist.
Note that @base_platform may include the container image name of the base platform, formatted as
@base_platform_name+base_container_image. This string is provided to the pilot for configuring the
container environment before executing the payload, but it is not utilized by the brokerage.
Checks for Releases, Caches, or Nightlies
Checks are as follows for releases, caches, and nightlies:
‘any’ or cvmfs_tag must be included in the
cvmfslist, where cvmfs_tag is atlas for standard releases and caches or nightlies for nightlies. In addition,‘any’ or ‘/cvmfs’ must be included in the
containerslist, orthe task
sw_platformis extracted from the taskarchitectureand must be included in thecmtconfigslist.
If the above is not the case,
‘any’ must be in the
containerslist orbase_platformin the taskarchitecturemust be empty, andthe task
sw_platform,sw_project, andsw_versionmust be equal tocmtconfig,project, andreleaseof a tag in thetagslist.
Network Weight
The network data sources are
the Network Weather Service as the dynamic source, and
the CRIC closeness as a semi static source.
Given the accuracy of the data and the timelapse from decision to action, the network weight only aims to provide a simple, dynamic classification of links. It is currently calculated as:
where the queued and throughput weight are calculated as in the plot below:
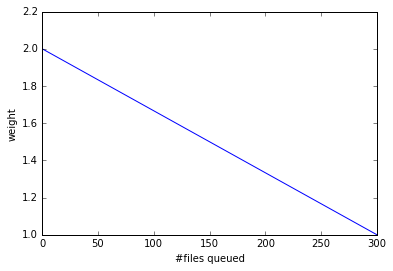
queuedWeight
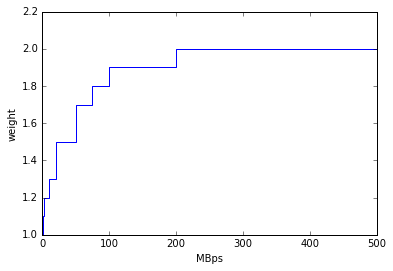
throughputWeight
It uses the most recent available data, so preferably data of the last 1 hour, if not available of last 1 day, if not available of last 1 week. FTS Mbps are used, which are filled from Chicago elastic search. If there are no available network metrics, the AGIS closeness (0 best to 11 worst) is used in a normalized way
Timeout Rules
1 hour for pending jobs
4 hours for defined jobs
12 hours for assigned jobs
7 days for throttled jobs
2 days for activated or starting jobs
4 hours for activated or starting jobs with job.currentPriority>=800 at the queues where
laststartin theSiteDatatable is older than 2 hours or the queue status is test or offline30 min for sent jobs
21 days for running jobs
2 hours for heartbeats from running or starting jobs. Each
workflowcan define own timeout value usingHEARTBEAT_TIMEOUT_<workflow>the above
HEARTBEAT_TIMEOUT_<workflow>for transferring jobs with theworkflowand own stage-out mechanism that sets not-null job.jobSubStatus3 hours for holding jobs with job.currentPriority>=800, while days for holding jobs with job.currentPriority<800
transtimehidays for transferring jobs with job.currentPriority>=800, whiletranstimelodays for transferring jobs with job.currentPriority<800disable all timeout rules when the queue status is paused or the queue has disableReassign in
catchallfast rebrokerage for defined, assigned, activated, or starting jobs at the queues where
nQueue_queue(gshare)/nRun_queue(gshare) is larger than
FAST_REBRO_THRESHOLD_NQNR_RATIOnQueue_queue(gshare)/nQueue_total(gshare) is larger than
FAST_REBRO_THRESHOLD_NQUEUE_FRACnQueue_queue(gshare) is larger than
FAST_REBRO_THRESHOLD_NQUEUE_<gshare>. Unless the gshare defines the parameter it doesn’t trigger the fast rebrokeragenSlots is not defined in the
Harvester_Slotstable since it intentionally cause large nQueue when nRun is small
Special Brokerage for ATLAS Full-chain
There is a mechanism in the ATLAS production task and job brokerages to assign an entire workflow (full-chain)
to a specific nucleus.
The main idea is to avoid data transfers between the nucleus and satellites, and burst-process all data
on the nucleus to deriver the final products quickly.
The nuclei are defined as bare nuclei by adding
bareNucleus=only or bareNucleus=allow in the catchall field in CRIC.
The former accepts only full-chain workflows while the latter accepts normal workflows in addition to full-chain
workflows. Tasks can set the fullChain parameter to use the mechanism. The value can be
only to be assigned to a nucleus with bareNucleus=only,
require to be assigned to a nucleus with bareNucleus=only or bareNucleus=allow, or
capable.
When capable is set, the task is assigned to the same nucleus as that of the parent task only if the parent task was assigned to a bare nucleus. Otherwise, capable is ignored and the task can go to a normal nucleus.
Once a task with the fullChain parameter is assigned to a bare nucleus, the job brokerage sends jobs only
to the queues associated to the nucleus. On the other hand. if a normal task is assigned to a bare nucleus
with bareNucleus=allow
or a task with fullChain = capable is assigned to a normal nucleus, the job brokerage sends jobs to the
queues associated to satellites in addition to the nucleus.
ATLAS Analysis Job Brokerage
This is the ATLAS analysis job brokerage flow:
First, the brokerage counts the number of running/queued jobs/cores for the user (or the working group if the task specifies
workingGroup), checks the global disk quota, and check the classification of the task. The brokerage throttles the task (not going to submit jobs for the task) if ANY of the following conditions holds:Number of User Jobs Exceeds Caps
the number of running jobs is larger than
CAP_RUNNING_USER_JOBSthe number of queued jobs is larger than 2 ×
CAP_RUNNING_USER_JOBSthe number of running cores is larger than
CAP_RUNNING_USER_CORESthe number of queued cores is larger than 2 ×
CAP_RUNNING_USER_CORES
For the working group it usesCAP_RUNNING_GROUP_JOBSandCAP_RUNNING_GROUP_CORESinstead.User’s Usage Exceeds Quota
the global disk quota exceeds
User Analysis Share Usage Exceeds its Target and the Task is in Lower Class
Currently this part of throttle is only for User Analysis share. Tasks in other shares are immune to it(For task and site classification, see Site & Task Classification)the User Analysis task is in class C , and User Analysis share usage > 90% of its target
the User Analysis task is in class B , and User Analysis share usage > 95% of its target
the User Analysis task is in class A , and User Analysis share usage > max(
USER_USAGE_THRESHOLD_A/(# of user’s running slots in hi-sites), 1)*100% of its target
Next, the brokerage generates the list of preliminary candidates as follows:
Take all queues with type=’analysis’ or ‘unified’.
Exclude queues if
excludedSiteis specified and the queues are included in the list.Exclude queues if
includedSiteis specified and the queues are not included in the list. Pre-assigned queues are specified inincludedSiteorsite.
Then, the brokerage filters out preliminary candidates that don’t pass any of the following checks: There are two types of filters, filters for persistent issues and filters for temporary issues.
- Filters for persistent issues
The queue status must be online unless the queues are pre-assigned.
Input data locality check to skip queues if they don’t have input data locally. This check is suppressed if
taskPriority≥ 2000,ioIntensity≤IO_INTENSITY_CUTOFF_USER, or the last successful brokerage cycle happened more thanDATA_CHECK_TIMEOUT_USERhours ago.Check with
MAX_DISKIO_DEFAULTlimit. It is possible to overwrite the limit for a particular queue through themaxDiskIO(in kB/sec per core) field in CRIC. The limit is applied in job brokerage: when the average diskIO per core for running jobs in a queue exceeds the limit, the next cycles of job brokerage will exclude tasks withdiskIOhigher than the defined limit to progressively get the diskIO under the threshold.CPU Core count matching.
Skip VP queues if the task specifies
avoidVPor those queues are overloaded.Availability of ATLAS release/cache. This check is skipped when queues have ANY in the
releasesfiled in CRIC. If queues have AUTO in thereleasesfiled, the brokerage uses the information published in a json by CRIC as explained at this section.Queues publish maximum (and minimum) memory size per core. The expected memory site of each job is estimated for each queue as
\[(baseRamCount + ramCount \times coreCount) \times compensation\]if
ramCountUnitis MBPerCore, or\[(baseRamCount + ramCount) \times compensation\]if
ramCountUnitis MB, where compensation is 0.9, avoiding sending jobs to high-memory queues when their expected memory usage is close to the lower limit. Queues are skipped if the estimated memory usage is not included in the acceptable memory ranges.The disk usage for a job is estimated as
\[(0 \: or \: inputDiskCount) + outDiskCount \times inputDiskCount + workDiskCount\]inputDiskCount is the total size of job input files. The first term in the above formula is zero if the queues are configured to read input files directly from the local storage.
maxwdiris divided by coreCount at each queue and the resultant value must be larger than the expected disk usage.DISK size check, usable space in the local storage has to be over
STORAGE_MIN_FREE_SIZEfor input andSTORAGE_MIN_FREE_SIZE_OUTPUTfor output.Skip blacklisted storage endpoints.
Analysis job walltime is estimated using the same formula as that for production jobs. The estimated walltime must be between
mintimeandmaxtimeat the queue.For scout, merge, or walltime-undefined jobs, skip queues if their
maxtimeis less than 24 hours.Skip queues without pilots for the last 3 hours.
- Filters for temporary issues
Skip queues if there are many jobs from the task closed or failed for the last
TW_DONE_JOB_STAThours. (nFailed + nClosed) must be less than max(2 × nFinished,MIN_BAD_JOBS_TO_SKIP_PQ).Skip queues if defined+activated+assigned+starting > 2 × max(20, running).
Skip queues if the user has too many queued jobs there.
- Filters to control user queue length on each PQ per ghsare: Analysis Stabilizer
First, decide whether the PQ can be throttled. The PQ will NOT be throttled if it does not have enough queuing jobs; that is, when any condition of the following is satisfied:
nQ(PQ) <
BASE_QUEUE_LENGTH_PER_PQnQ(PQ) <
BASE_EXPECTED_WAIT_HOUR_ON_PQ* trr(PQ)
where trr stands for to-running-rate = number of jobs getting from queuing to running per hour in the PQ; it is evaluated according to jobs with starttime within last 6 hours
If the PQ does not meet any condition above, it can be throttled. Then compute nQ_max(PQ) (i.e. the affordable max queue length of each PQ), which is the max among the following values:
STATIC_MAX_QUEUE_RUNNING_RATIO* nR(PQ)MAX_EXPECTED_WAIT_HOUR* trr(PQ)
Next, compute what percentage of nQ_max(PQ) is for the user:
percentage(PQ, user) = max( nR(PQ, user)/nR(PQ) , 1/nUsers(PQ) )
Finally, the max value among the following, called max_q_len , will be used to throttle nQ(PQ, user)
BASE_QUEUE_RATIO_ON_PQ* nR(PQ)nQ_max(PQ) * percentage(PQ, user)
Thus, if nQ(PQ, user) > max_q_len , the brokerage will temporarily exclude the PQs in which the user of the task already has enough queuing jobs
Finally, it calculates the brokerage weight for remaining candidates using the following formula.
Original basic weight
\[weight = \frac {running + 1} {(activated + assigned + starting + defined + 1)}\]The brokerage uses the largest one as the number of running jobs among the following numbers:
The actual number of running jobs at the queue, Rreal.
min(nBatchJob, 20) if Rreal < 20 and nBatchJob (the number of running+submitted batch workers at PQ) > Rreal. Mainly for bootstrap.
numSlots if it is set to a positive number for the queue to the proactive job assignment.
The number of starting jobs if numSlots is set to zero, which is typically useful for Harvester to fetch jobs when the number of available slots dynamically changes.
Currently original basic weight is used in brokerage.
New basic weight
New basic weight = \(W_s \cdot W_q\) , where
- \(W_s\)weight from site-class
For jobs in User Analysis and Express Analysis: \(W_s\) is shown in the table
Task Class
hi-site
mid-site
lo-site
S or A
\(N_j\)
\(\epsilon_1\)
\(\epsilon_2\)
B
\(\epsilon_2\)
\(N_j\)
\(\epsilon_1\)
C
\(\epsilon_2\)
\(\epsilon_1\)
\(N_j\)
where
\(N_j\): estimated number of jobs to submit in the brokerage cycle
\(\epsilon_1\), \(\epsilon_2\): some small positive numbers (not fixed) to avoid dead zero; \(\epsilon_1 > \epsilon_2\)
The purpose is to broker time-sensitive tasks to high-appropriateness analysis sites more, and vice versa.
(For task and site classification, see Site & Task Classification)
For other analysis shares (group shares, ART, etc.): \(W_s = N_j\) . (Task- and site-classification are NOT considered)
\(W_q\): weight from queue length
\[W_{q} = \frac { \text{max_q_len}(PQ, user) - \text{nQ}(PQ, user) - N_{j} / N_{PQ} } { ( \sum_{\text{candidate PQs}} ( \text{max_q_len}(PQ, user) - \text{nQ}(PQ, user) ) ) - N_{j} }\]where \(N_{PQ}\) = number of candidate PQs; \(\text{nQ}\) and \(\text{max_q_len}\) are defined in Analysis Stabilizer
The purpose is to control the queue length in the same way of Analysis Stabilizer.
New basic weight will soon be deployed to replace the original basic weight
If all queues are skipped due to the persistent issues, the brokerage tries to find candidates without the input data locality check. If all queues are still skipped, the task is pending for 20 min. Otherwise, the remaining candidates are sorted by weight, and the best 10 candidates are taken.